5. 実践編: MRI画像のセグメンテーション¶
![]()
画像を対象とした深層学習の応用技術には様々なものがあります.例えば,画像の中の個別の物体の周りを矩形で囲むようにして検出する物体検出や,画像内で個別物体が占める領域を認識する画像セグメンテーションなどがあります.
物体検出は,対象物体の「種類」と「位置」を認識する技術であるといえます.
 (上図:物体検出の例.矩形で対象物体を囲い,そのクラスを答えるタスク.元画像はPascal VOCデータセットより.これにChainerCVによるFaster R-CNN(両者とも後述)を適用した結果.)
(上図:物体検出の例.矩形で対象物体を囲い,そのクラスを答えるタスク.元画像はPascal VOCデータセットより.これにChainerCVによるFaster R-CNN(両者とも後述)を適用した結果.)
画像セグメンテーションには2種類あります.1つは,個別の物体を区別するInstance-aware Segmentationです.もう一つは,同一クラスの物体であれば個を区別しないSemantic Segmentationです.今回は,後者を扱います.
 (上図:Semantic Segmentationの例.ピクセル単位でクラス分類を行うタスク.画像を,予め決められた数の色で塗り絵をするようなイメージ.図はCityscapesデータセットを用いて学習したあるセグメンテーションモデルの出力結果例.)
(上図:Semantic Segmentationの例.ピクセル単位でクラス分類を行うタスク.画像を,予め決められた数の色で塗り絵をするようなイメージ.図はCityscapesデータセットを用いて学習したあるセグメンテーションモデルの出力結果例.)
画像セグメンテーションは,4章で扱った画像全体に対して一つのクラスを割り当てる分類問題とは異なり,画像内の全ピクセルを,ピクセルごとに分類していきます.そのため,Pixel labeling タスクとも呼ばれます.これは,対象物体の「種類」と「位置」と「形」を認識する技術であるといえるでしょう.
今回は,深層学習フレームワークChainerを用いて,このSemantic Segmentationタスクに取り組んでみましょう.
5.1. 環境構築¶
ここで用いるライブラリは,
- Chainer
- CuPy
- ChainerCV
- matplotlib
です.Google ColabではChainer, CuPy, matplotlibはすでにインストールされているため,ChainerCVを以下のようにしてインストールします.以下のセルを実行してください.
[1]:
!pip install chainercv
Collecting chainercv
Downloading https://files.pythonhosted.org/packages/e8/1c/1f267ccf5ebdf1f63f1812fa0d2d0e6e35f0d08f63d2dcdb1351b0e77d85/chainercv-0.13.1.tar.gz (260kB)
|████████████████████████████████| 266kB 6.4MB/s
Requirement already satisfied: chainer>=6.0 in /usr/local/lib/python3.6/dist-packages (from chainercv) (6.5.0)
Requirement already satisfied: Pillow in /usr/local/lib/python3.6/dist-packages (from chainercv) (4.3.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.6/dist-packages (from chainer>=6.0->chainercv) (3.0.12)
Requirement already satisfied: six>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from chainer>=6.0->chainercv) (1.12.0)
Requirement already satisfied: typing<=3.6.6 in /usr/local/lib/python3.6/dist-packages (from chainer>=6.0->chainercv) (3.6.6)
Requirement already satisfied: protobuf>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from chainer>=6.0->chainercv) (3.10.0)
Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from chainer>=6.0->chainercv) (41.6.0)
Requirement already satisfied: numpy>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from chainer>=6.0->chainercv) (1.17.4)
Requirement already satisfied: typing-extensions<=3.6.6 in /usr/local/lib/python3.6/dist-packages (from chainer>=6.0->chainercv) (3.6.6)
Requirement already satisfied: olefile in /usr/local/lib/python3.6/dist-packages (from Pillow->chainercv) (0.46)
Building wheels for collected packages: chainercv
Building wheel for chainercv (setup.py) ... done
Created wheel for chainercv: filename=chainercv-0.13.1-cp36-cp36m-linux_x86_64.whl size=537352 sha256=1834a92c8ca4cbada5e34af649c0f4f5437722a0889aeca40924e27eace9bdf8
Stored in directory: /root/.cache/pip/wheels/ea/10/01/e221beaa4b3d8341aa819a39ab8d4677457c79c81f521f3a94
Successfully built chainercv
Installing collected packages: chainercv
Successfully installed chainercv-0.13.1
インストールが完了したら,以下のセルを実行して,各ライブラリのバージョンなどを確認します.
[2]:
import chainer
import cupy
import chainercv
import matplotlib
chainer.print_runtime_info()
print('ChainerCV:', chainercv.__version__)
print('matplotlib:', matplotlib.__version__)
Platform: Linux-4.14.137+-x86_64-with-Ubuntu-18.04-bionic
Chainer: 6.5.0
ChainerX: Not Available
NumPy: 1.17.4
CuPy:
CuPy Version : 6.5.0
CUDA Root : /usr/local/cuda
CUDA Build Version : 10010
CUDA Driver Version : 10010
CUDA Runtime Version : 10010
cuDNN Build Version : 7603
cuDNN Version : 7603
NCCL Build Version : 2402
NCCL Runtime Version : 2402
iDeep: 2.0.0.post3
ChainerCV: 0.13.1
matplotlib: 3.1.1
5.2. Semantic Segmentationについて¶
Semantic Segmentationは,Computer Visionの分野で現在も活発に研究が行われているタスクの一つで,入力画像の画素ひとつひとつに対して,なんらかのクラスを与えていくという問題です.しかし,人間ですら,あるピクセルひとつだけを見てそれが何かを推測するのは不可能です.そのため,いかにして周囲のピクセルの情報を加味しながら,ひとつひとつのピクセルの分類を行うか,が重要となります.
ニューラルネットワークを用いてこの問題を解く場合は,「画像を入力して,画像を出力するネットワーク」を作って学習することになります.そのため,入力画像とペアになる正解ラベル画像は,同じ大きさを持つ,各ピクセルの所属クラス番号が入ったシングルチャンネルの画像とすることが一般的です.
ネットワークの出力は,\(C\)クラス分類をする場合は\(C\)チャンネルの画像になります.それを各ピクセルごとにチャンネル方向にSoftmax関数を適用して確率ベクトルにし,正解のクラスの値が大きくなるよう(高い確信をもって正解クラスを予測できるよう)にすることで学習を行います.画像分類(Classification)の際の目的関数の計算を,ピクセルごとに行っていると考えることもできます.そして,ピクセルごとの分類誤差を,画像サイズ分だけ足し合わせたものが最小化の対象となります.
ここで,\(C=2\)の場合だけは,ネットワークの出力を\(1\)チャンネルにし,損失関数をSigmoid Cross Entropyとすることもあります.
5.3. 使用するデータセット¶
これから使用するデータセットは,心臓MRI画像(短軸像)と,それに専門家がラベルを付けたものです.データについて詳しくはこちらをご参照ください[1, 2, 3].
まずは,データをダウンロードします.これは配布元のデータセットを今回用いやすいように加工し終えたものです.
[3]:
!if [ ! -d train ]; then curl -L -O https://github.com/mitmul/chainer-handson/releases/download/SegmentationDataset/train.zip && unzip train.zip && rm -rf train.zip; fi
!if [ ! -d val ]; then curl -L -O https://github.com/mitmul/chainer-handson/releases/download/SegmentationDataset/val.zip && unzip val.zip && rm -rf val.zip; fi
次に,このデータセットから抜き出した画像ペアの例を示します.下のセルを実行してみてください.
[4]:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# PILライブラリで画像を読み込む
img = np.asarray(Image.open('train/image/000.png'))
label = np.asarray(Image.open('train/label/000.png'))
# matplotlibライブラリを使って2つの画像を並べて表示
fig, axes = plt.subplots(1, 2)
axes[0].set_axis_off()
axes[0].imshow(img, cmap='gray')
axes[1].set_axis_off()
axes[1].imshow(label, cmap='gray')
plt.show()
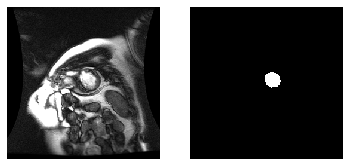
左側がMRI画像,右側がそれに対し専門家が作成した左心室の部分をマスクした画像となっています.右側のマスク画像のうち,白く塗りつぶされている領域が,今回見つけ出したい左心室の領域となっています.左心室の大きさは,画像ごとに異なっており,形もまた様々です.ただし,画像全体に対して左心室が占める領域は比較的小さいということは共通しています.
今回は,MRI画像データを,提供元が配布している形式(DICOM形式)から扱いやすいよう一般的な画像フォーマット(PNG)に変換して用いますが,そのための作業については説明しません.もし今回用いるMRI画像群のデータ整形の方法について興味をお持ちの方は,以前行われたKaggleのコンペティションに関連して提供されているこちらのチュートリアルをご参照ください:Kaggle competition: Second Annual Data Science Bowl [4])
今回用いるデータセットの元となったデータは,医療画像では一般的な画像フォーマットである DICOM 形式で配布されており,画像サイズは 256 x 256 のグレースケール画像になっています.今回は,これをあらかじめPNG画像に変換してあります.ラベル画像は,同じ大きさの二値画像となっており,左心室の領域内部のピクセルは画素値として1を持ち,それ以外のピクセルは0で埋められています.今回用いる学習用データセットは234枚の画像ペア(グレースケールのMRI画像と,対応する二値のラベル画像のペア)からなり.検証用データは,26枚の画像からなります.検証用データは学習用データとは別に用意されたものです.
5.3.1. Chainerを用いた学習の流れ¶
今回は,4章で扱ったChainerを使ってSemantic Segmentationに取り組みます.画像から画像を出力するネットワークを記述します. 4章でも述べたように,Chainerには,学習ループ抽象化のためのクラスであるTrainerが用意されています.これを用いて,左心室であるかそれ以外かの2クラスにすべてのピクセルを分類するSemantic Segmentationタスクに取り組みます.Trainerを使って学習を行う際にユーザがする必要がある準備について再度復習しましょう.
- Datasetオブジェクトの準備(学習に使うデータを一つ一つ返す)
- DatasetオブジェクトをIteratorにくるむ(Dataset内のデータをバッチサイズ分束ねて返す)
- モデルの定義(学習対象になるニューラルネットワーク.
chainer.Chainクラスを継承して書く) - 最適化手法の選択(
chainer.optimizers以下にある最適化手法から選ぶ) Updaterオブジェクトの準備(IteratorとOptimizerをとり,実際の学習部分(パラメータアップデート)を行うもの)Trainerオブジェクトの作成(学習ループの管理)
Trainerに含まれるコンポーネントは,以下のような関係になっています.

Updaterは,IteratorからDatasetにあるデータを指定したバッチサイズ数だけ取り出し,Modelに与えて目的関数の値を計算し,Optimizerによってパラメータを更新する,という一連の作業(これが1 iterationになります)を隠蔽しています.TrainerはExtensionという拡張機能を使うことができ,指定したタイミング(毎iterationや,毎epoch)でログを取る,目的関数の値や精度のプロットを描画して保存,などを自動的に行うことができます.
Chainerを用いてネットワークの学習を記述する場合は,上の図の内側から順に定義していき,最後にすべてを持ったTrainerオブジェクトを作成し,trainer.run()のようにして学習を開始することになります.
(Trainerを使わず,自分で学習ループを記述することもできますが,今回はTrainerを使用することを前提とします.自分で学習ループを記述する方法を知りたい場合は4章を参照してください)
5.4. 全結合型ニューラルネットワークによるセグメンテーション¶
まずは単純なモデルから学習を開始します.全結合層3つからなるニューラルネットワークを使って,MRI画像を入力にとり,左心室らしさのグレースケール画像を出力するモデルを学習しましょう.
5.4.1. データセットの準備¶
まずはデータセットの準備をします.Chainerにはいくつかの便利なデータセットまわりのクラスが用意されています.ImageDatasetは,画像ファイルへのファイルパスのリストを渡して初期化してやると,そのパスにある画像を学習時にディスクから読み込み,それを返してくれるようなデータセットクラスです.TupleDatasetは,複数のデータセットオブジェクトを渡して初期化すると,それらから同じインデックスを持つデータをタプルに束ねて返してくれるようなデータセットオブジェクトを作成するクラスです.(Pythonのzipと同様です.)
今回はSemantic Segmentationなので,入力も出力も画像です.なので,2つのImageDatasetオブジェクトを作成します.以下のセルを実行してください.
[5]:
import glob
from chainer import datasets
def create_dataset(img_filenames, label_filenames):
img = datasets.ImageDataset(img_filenames)
img = datasets.TransformDataset(img, lambda x: x / 255.) # 0-1に正規化
label = datasets.ImageDataset(label_filenames, dtype=np.int32)
dataset = datasets.TupleDataset(img, label)
return dataset
上の関数は,入力画像のファイルパスのリストimg_filenamesと,正解ラベル画像(0 or 1の画素値を持つ二値画像)のファイルパスのリストlabel_filenamesを与えて,2つのデータセットオブジェクトをTupleDatasetで束ねて返すものになっています.
imgは入力画像のデータセットですが,まるで入力画像が入ったリストのように振る舞い,img[i]はi番目の画像を返します([i]でアクセスしたときに初めてディスクから画像が読み込まれます).
labelも同様に,ラベル画像のリストのように振る舞います.これらをTupleDatasetで束ねて作ったdatasetは,dataset[i]でアクセスすると(img[i], label[i])というタプル(値の2つ以上の集まり)を返すものになります.(これはimgとlabelが同じ長さのリストの場合,zip(img, label)の結果と同じです.)
次に,この関数内の2行目において,ImageDatasetで作った入力データセットを元にTransformDatasetという新しいデータセットを作っています.TransformDatasetは,第1引数に与えられたデータセットにアクセスする際に第2引数に与えた関数を適用してから返すようにできるクラスで,任意の関数を与えてデータを変換させる処理をはさむことができます.ここでは,変換を行う関数をlambda関数を使って与え,単純に値域を\([0, 1]\)に変換するだけの処理を行っています.この他,例えば内部で乱数によって様々な変換(画像の場合,ランダムに左右反転を行ったり,ランダムな角度で回転をしたり,などがよく行われます)を施す関数を引数として渡すことでData
augmentationを簡単に実装することができます.
このcreate_dataset関数を使って学習用・検証用それぞれのデータセットオブジェクトを作成しましょう.下のセルを実行してください.
[6]:
def create_datasets():
# Python標準のglobを使ってMRI画像ファイル名/ラベル画像ファイル名の一覧を取得
train_img_filenames = sorted(glob.glob('train/image/*.png'))
train_label_filenames = sorted(glob.glob('train/label/*.png'))
# リストを渡して,データセットオブジェクト train を作成
train = create_dataset(train_img_filenames, train_label_filenames)
# 同様のことをvalidationデータに対しても行う
val_img_filenames = sorted(glob.glob('val/image/*.png'))
val_label_filenames = sorted(glob.glob('val/label/*.png'))
val = create_dataset(val_img_filenames, val_label_filenames)
return train, val
この関数create_datasets()では,まずPython標準に備わっているglobを使って,.pngの拡張子を持つ画像ファイルを指定したディレクトリ以下から探してきて,ファイルパスが格納されたリストを作ります.次に,入力画像とラベル画像のファイルリストが同じインデックスで対応したデータをそれぞれ指すように,sortedを使ってファイル名をソートしています(glob関数で列挙されるファイルリストは必ずしもソートされているとは限りません).そのあと,それらのファイル名リストを先程のcreate_dataset関数に渡して,データセットオブジェクトを作成しています.同様のことを検証用の画像ファイルに対しても行い,trainとval2つのデータセットオブジェクトを作成して返します.
ではこの関数を呼んでみましょう.下のセルを実行してください.
[7]:
train, val = create_datasets()
print('Dataset size:\n\ttrain:\t{}\n\tvalid:\t{}'.format(len(train), len(val)))
Dataset size:
train: 234
valid: 26
この関数を呼べば,訓練用データセットオブジェクトと検証用データセットオブジェクトを作成できます.データセットオブジェクトは基本的にはリストとして扱うことができます.例えば組み込み関数のlen()を使っていくつのデータが含まれているかを知ることができます.
5.4.2. モデルの定義¶
次に,訓練するモデルの定義です.ここでは4章でも扱った全結合型ニューラルネットワークを使います.
[8]:
import chainer
import chainer.functions as F
import chainer.links as L
class MultiLayerPerceptron(chainer.Chain):
def __init__(self, out_h, out_w):
super().__init__()
with self.init_scope():
self.l1 = L.Linear(None, 100)
self.l2 = L.Linear(100, 100)
self.l3 = L.Linear(100, out_h * out_w)
self.out_h = out_h
self.out_w = out_w
def forward(self, x):
h = F.relu(self.l1(x))
h = F.relu(self.l2(h))
h = self.l3(h)
n = x.shape[0]
return h.reshape((n, 1, self.out_h, self.out_w))
ここでは3つの全結合層を使い,活性化関数にReLUを用いる形で繋げています.最後に,正解のマスク画像とそのまま比較しやすいように,画像の形にreshapeして返しています.つまり,1次元配列を2次元配列に変形しています.
ここで,出力のチャンネル数は1で,各ピクセルが左心室である確率を表します.
5.4.3. Trainerの定義¶
次にTrainerを定義しましょう.Trainerオブジェクトを作成して返してくれるcreate_trainer関数を定義しましょう.各引数の定義は以下の通りです‥
- ミニバッチサイズ(batchsize)
- 学習用データセット(train)
- 検証用データセット(val)
- 学習を停止するタイミング(stop)
- 使用するデバイス(device)←
-1にするとCPU,>=0の場合はそのIDを持つGPU
以下のセルを実行してください.
[9]:
from chainer import iterators
from chainer import training
from chainer import optimizers
from chainer.training import extensions
def create_trainer(batchsize, train, val, stop, device=-1):
# 先程定義したモデルを使用
model = MultiLayerPerceptron(out_h=256, out_w=256)
# ピクセルごとの二値分類なので,目的関数にSigmoid cross entropyを,
# 精度をはかる関数としてBinary accuracyを指定しています
train_model = L.Classifier(
model, lossfun=F.sigmoid_cross_entropy, accfun=F.binary_accuracy)
# 最適化手法にAdamを使います
optimizer = optimizers.Adam()
optimizer.setup(train_model)
# データセットから,指定したバッチサイズ数のデータ点をまとめて取り出して返すイテレータを定義します
train_iter = iterators.MultiprocessIterator(train, batchsize)
val_iter = iterators.MultiprocessIterator(val, batchsize, repeat=False, shuffle=False)
# イテレータからデータを引き出し,モデルに渡して,目的関数の値を計算し,backwardしてパラメータを更新,
# までの一連の処理を行う updater を定義します
updater = training.StandardUpdater(train_iter, optimizer, device=device)
# 様々な付加機能をExtensionとして与えられるTrainerを使います
trainer = training.trainer.Trainer(updater, stop)
logging_attributes = [
'epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy']
trainer.extend(extensions.LogReport(logging_attributes))
trainer.extend(extensions.PrintReport(logging_attributes))
trainer.extend(extensions.PlotReport(['main/loss', 'val/main/loss'], 'epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/accuracy', 'val/main/accuracy'], 'epoch', file_name='accuracy.png'))
trainer.extend(extensions.Evaluator(val_iter, optimizer.target, device=device), name='val')
return trainer
この関数定義の中の最後の方では,複数の Extension を追加しています.これらはログのファイルへの自動保存(LogReport)やその標準出力への表示(PrintReport),目的関数の値や精度のプロットの自動作成(PlotReport),指定したタイミングおきにvalidationデータで評価(Evaluator),などをしてくれる拡張機能です.
この他にも様々な拡張機能が使える様になっています.こちらにあるExtensionの一覧から,使い方やできることを調べることができます: Trainer extensions
5.4.4. 学習¶
これで学習の準備ができました. あとは作成したtrainerからrun()関数を呼び出すだけです.
下のセルを実行してください.
[10]:
%%time
trainer = create_trainer(64, train, val, (20, 'epoch'), device=0)
trainer.run()
epoch main/loss main/accuracy val/main/loss val/main/accuracy
1 1.06459 0.514054 0.763243 0.541347
2 0.766642 0.557265 0.678482 0.58342
3 0.669491 0.596515 0.661777 0.625739
4 0.64059 0.640895 0.605858 0.675552
5 0.576377 0.700222 0.520871 0.7438
6 0.498939 0.761138 0.443727 0.795278
7 0.400396 0.820358 0.324807 0.860446
8 0.28312 0.882238 0.213901 0.914947
9 0.190724 0.925966 0.147691 0.944379
10 0.123899 0.954501 0.0877821 0.968398
11 0.0746379 0.973691 0.0553097 0.980432
12 0.0512983 0.981973 0.0431525 0.984157
13 0.040367 0.985149 0.0354616 0.985986
14 0.0341428 0.986499 0.0321402 0.986762
15 0.0327328 0.986677 0.0307444 0.987055
16 0.0299803 0.987462 0.0296306 0.987203
17 0.0301438 0.987283 0.0292037 0.9872
18 0.0289293 0.98721 0.0289427 0.987285
19 0.028623 0.987605 0.0286088 0.987439
20 0.0282504 0.987593 0.0282954 0.987482
CPU times: user 31.7 s, sys: 1.92 s, total: 33.6 s
Wall time: 38.1 s
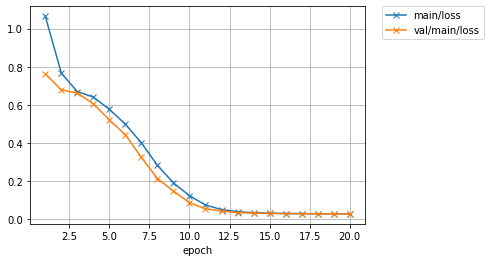
大体,学習に40秒程度かると思います.この時表示されたのはPrintReportというExtensionが出力したログの情報です.現在のエポック数,目的関数の値,精度(学習データセットに対してのものはmain/loss, main/accuracy,検証データセットに対してのものはval/main/loss, val/main/accuracy)が表示されています.
それでは次に,PlotReport拡張が出力したグラフを見てみましょう.学習が終了したら,以下の2つのセルを実行してみてください.
[11]:
from IPython.display import Image
Image('result/loss.png')
[11]:
[12]:
Image('result/accuracy.png')
[12]:
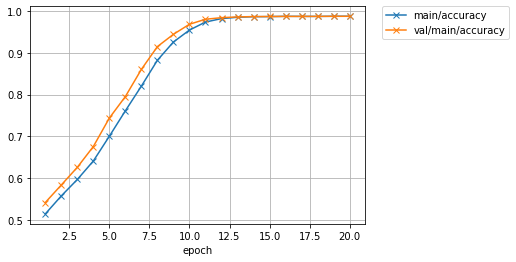
うまく学習が進んでいるようです.Training loss, Validation lossともにほぼ0近くまで下がっており,また両者のデータセットに対するAccuracyも最大の1に近づいていっています.
これらのプロットは,Trainerの初期化の際に渡すoutという引数で指定された場所に画像として保存されています.これは逐次更新されているので,実際には学習の途中でもその時点でのプロットを確認することができます.学習の進み具合を視覚的に確認するのに便利です.
5.4.5. 評価¶
さて,ここまでの結果をみると学習や検証データに対する性能は一見良好のようにみえます.特にAccuracyは最大値の1に近い値となっていました.しかし,この指標はどういう指標なのでしょうか?何をもって「精度(Accuracy)」と言っていたのでしょうか.
一般的にSemantic Segmentationの結果は上で「accuracy」と表示されていたPixel accuracyや,それとは異なる指標であるMean Intersection over Union (mIoU)といった値で評価が行われます.それぞれの定義は以下のようになっています.
正解クラスが\(i\)であるピクセルをモデルがクラス\(j\)に分類した数を\(N_{ij}\)とすると,クラス数が \(k\) のとき
です.では,改めてこの2つの値をValidationデータセットに対して,今学習したモデルを使って計算してみましょう.
今回は,これらの値を計算するために,ChainerCV [5]を用います.ChainerCVはコンピュータビジョンタスクで頻出する計算やモデル・データ等の扱いを統一的に行えるChainerの追加パッケージです.上の2つの指標をあらためて計算するために,ChainerCVが提供するSemantic Segmentationタスク用の評価指標計算のための関数を用いてみましょう.
以下のセルを実行してください.
[13]:
from chainer import cuda
from chainercv import evaluations
def evaluate(trainer, val, device=-1):
# Trainerオブジェクトから学習済みモデルを取り出す
model = trainer.updater.get_optimizer('main').target.predictor
# validationデータ全部に対して予測を行う
preds = []
for img, label in val:
img = cuda.to_gpu(img[np.newaxis], device)
pred = model(img)
pred = cuda.to_cpu(pred.data[0, 0] > 0)
preds.append((pred, label[0]))
pred_labels, gt_labels = zip(*preds)
# 評価をして結果を表示
evals = evaluations.eval_semantic_segmentation(pred_labels, gt_labels)
print('Pixel Accuracy:', evals['pixel_accuracy'])
print('mIoU:', evals['miou'])
evaluate(trainer, val, device=0)
Pixel Accuracy: 0.9874819242037259
mIoU: 0.693485709625507
2つの数字が表示されました.
Pixel Accuracyの値はPrintReportが表示した val/main/accuracy と同じ値になっています.学習中に"accuracy"として表示していたものは,Pixel Accuracyと同じものでした.こちらは,とても高い値を示しています.最大値が1であるので0.98というのは高い数値です.
一方で,同じ最大値1の指標であるmIoU(miou)が思ったより低いことが分かります.なぜでしょうか.
Pixel Accuracyは画像全体の画素数に対して,true positive + true negative(つまり,黒を黒,白を白と当てられた合計数) の割合を見るため,画像全体に対して negative ( 黒)が多い場合は true positive (白を当てられた数)が小さくてもtrue negativeが大きければ結果としてPixel Accuracyは高い値になります.つまり,class imbalance(白と黒の数が大きく違う)が起きている際に,少ないクラスへの予測誤差の影響が相対的に小さくなるということです.
一方,mIoU の場合は,予測と正解の両画像における「positiveとtrueの和領域」(白と予測した部分と,白が正解である領域の和)に対する「true positive」(白という予測が正解していた領域)の割合を見るので,画像全体の大きさに影響されません.わかりやすく図にすると,以下のようになります.

この図の言葉で書くと,IoUは,
となります.true_positiveはTrue Positiveのピクセル数,positiveは予測画像中で1の値をとるピクセル数,trueは正解画像中で1の値をとるピクセル数です.
では,実際に得られたモデルを使って validation データに予測を行った結果を可視化して,「Pixel Accuracy は高いが mIoU が低い」ことの問題を確認してみましょう.以下のセルを実行してください.
[14]:
def show_predicts(trainer, val, device=-1, n_sample=3):
# Trainerオブジェクトから学習済みモデルを取り出す
model = trainer.updater.get_optimizer('main').target.predictor
for i in range(n_sample):
img, label = val[i]
img = cuda.to_gpu(img, device)
pred = model(img[np.newaxis])
pred = cuda.to_cpu(pred.data[0, 0] > 0)
fig, axes = plt.subplots(1, 2)
axes[0].set_axis_off()
axes[0].imshow(pred, cmap='gray')
axes[1].set_axis_off()
axes[1].imshow(label[0], cmap='gray')
plt.show()
show_predicts(trainer, val, device=0)



左の列が予測ラベルで,右の列が正解ラベルです.3行目に顕著なように,予測のpositive領域(白い領域)は正解の領域に対して小さくなっています.Pixel Accuracyは大部分を占めている黒い部分も含めての正解率ですので,Pixel Accuracyは評価指標として今回のようなデータセットにはあまり合っていない可能性があります.それに対しmIoUは今回のような画像中の予測対象領域の割合が少ない場合に有効な指標となります.
以降は,どうやってmIoUを改善するかに取り組んでみましょう.
5.5. 畳み込みネットワークを用いたセグメンテーション¶
mIoU改善のため,モデルを全結合層のみから構成されるものから,画像関連のタスクで多く用いられる,畳み込み層を用います.それに加えてより深い(層数の多い)モデルに変えてみましょう.今回用いるLinkは,Convolution2DとDeconvolution2Dの2つだけです.それぞれ,カーネルサイズ(ksize),ストライド(stride),パディング(pad)を指定することができます.これらがどのように出力を変化させるかを,まずはまとめてみましょう.
5.5.1. Convolutionレイヤ¶
Convolution2DというLinkは,一般的な畳込みレイヤの実装です.Convolutionがどのようなレイヤかは前章で説明しました.畳み込み層のパラメータを設定する際には,以下の点を知っておくと便利です.
- paddingを使って計算後の出力サイズを維持しやすくするために,奇数のカーネルサイズにする(\(\lfloor {\rm ksize} / 2 \rfloor\)をpadに指定すると,stride=1の際に画像サイズが変わらなくなる)
- 出力feature mapを縮小したい場合は,>1の値をstrideに与える(stride=nだと変換後の画像の縦横はそれぞれ元の1/nになる)
- 出力サイズは,\(({\rm input\_size} - {\rm ksize} + {\rm pad} \times 2) / {\rm stride} + 1\)になる.つまり,strideを大きくすると出力特徴マップは小さくなる.
5.5.2. Deconvolutionレイヤ¶
Deconvolution2Dは,歴史的な経緯からその名とは異なり数学的な意味でのdeconvolutionではありません.実際に適用している操作からTransposed convolutionや,Backward convolutionとよばれることもあります.Deconvolution2Dとはフィルタの適用の仕方はConvolutionと同じですが入力特徴マップの値を飛び飛びに配置するなどの処理が入る部分が異なる処理のことです.Deconvolution2Dレイヤのパラメータを設定する際には,以下の点を知っておくと便利です.
- カーネルサイズをstrideで割り切れる数にする(checker board artifactを防ぐため.こちらを参考のこと:Deconvolution and Checkerboard Artifacts)
- 出力サイズは,\({\rm stride} \times ({\rm input\_size} - 1) + {\rm ksize} - 2 \times {\rm pad}\)となるので,目的の拡大後サイズになるようパラメータを調整する
Deconvolution2Dにおいては,padが意味するものが少し直感的でないため,実際に行われる操作を説明した図を以下に用意しています.


気をつける点は,ksizeとstrideに従って配置・拡張したfeature mapの周囲を「削る量」がpadになっている点です.そのあと行われる演算自体はstride=1, pad=0のConvolutionと同じになります.
こちらに,非常にわかりやすく各種Convolution/Deconvolutionの計算を表したGIFアニメがあるので,参考にしてください:Convolution arithmetic
5.5.3. 全畳込みネットワーク¶
それではConvolution層とDeconvolution層からなるネットワークをChainerで書いてみます.以下のモデルは,Fully Convolutional Networkと呼ばれるネットワークに類似したものです.詳しくはこちらの文献を参照してください [6, 7, 8].
以下のFullyConvolutionalNetworkというモデルの定義には,FIXME_1 ~ FIXME_5まで,5つの定数が含まれていますが,値が与えられていません.それぞれは,Convolutionの出力側のチャンネル数になります.試しにこれを,
- FIXME_1 = 64
- FIXME_2 = 128
- FIXME_3 = 128
- FIXME_4 = 128
- FIXME_5 = 128
と書き換えて,下のセルを実行してみましょう.入力チャンネル数は,Noneを与えておくと,実行時に自動的に決定してくれます.
[15]:
from chainer import reporter
from chainer import cuda
from chainercv import evaluations
class FullyConvolutionalNetwork(chainer.Chain):
def __init__(self, out_h, out_w, n_class=1):
super().__init__()
with self.init_scope():
# L.Convolution2D(in_ch, out_ch, ksize, stride, pad)
# in_chは省略することができるので,
# L.Convolution2D(out_ch, ksize, stride, pad)
# とかくこともできます.
self.conv1 = L.Convolution2D(None, FIXME_1, ksize=5, stride=2, pad=2)
self.conv2 = L.Convolution2D(None, FIXME_2, ksize=5, stride=2, pad=2)
self.conv3 = L.Convolution2D(None, FIXME_3, ksize=3, stride=1, pad=1)
self.conv4 = L.Convolution2D(None, FIXME_4, ksize=3, stride=1, pad=1)
self.conv5 = L.Convolution2D(None, FIXME_5, ksize=1, stride=1, pad=0)
# L.Deconvolution2D(in_ch, out_ch, ksize, stride, pad)
# in_chは省略することができるので,
# L.Deconvolution2D(out_ch, ksize, stride, pad)
# と書くこともできます.
self.deconv6 = L.Deconvolution2D(None, n_class, ksize=32, stride=16, pad=8)
self.out_h = out_h
self.out_w = out_w
def forward(self, x):
h = F.relu(self.conv1(x))
h = F.max_pooling_2d(h, 2, 2)
h = F.relu(self.conv2(h))
h = F.max_pooling_2d(h, 2, 2)
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = self.conv5(h)
h = self.deconv6(h)
return h.reshape(x.shape[0], 1, h.shape[2], h.shape[3])
print(FullyConvolutionalNetwork(256, 256)(np.zeros((1, 1, 256, 256), dtype=np.float32)).shape[2:])
(256, 256)
FIXME_1 ~ FIXME_5を定数に書き換えた上で上のセルを実行すると,ネットワークの出力サイズが表示されます.今回の入力画像は(256, 256)サイズの画像ですから,出力が256 x 256という同じ大きさになっていれば正しく動作しています.
5.5.4. Classifierクラスの改良¶
次に,学習中にチェックするものとして,Pixel AccuracyだけでなくmIoUも追加するために,目的関数を計算するClassifierクラスを,自分でカスタマイズしたものに置き換えます.それは,以下のように定義されます.下記のセルを実行してみましょう.
[16]:
class PixelwiseSigmoidClassifier(chainer.Chain):
def __init__(self, predictor):
super().__init__()
with self.init_scope():
# 学習対象のモデルをpredictorとして保持しておく
self.predictor = predictor
def __call__(self, x, t):
# 学習対象のモデルでまず推論を行う
y = self.predictor(x)
# 2クラス分類の誤差を計算
loss = F.sigmoid_cross_entropy(y, t)
# 予測結果(0~1の連続値を持つグレースケール画像)を二値化し,
# ChainerCVのeval_semantic_segmentation関数に正解ラベルと
# 共に渡して各種スコアを計算
y, t = cuda.to_cpu(F.sigmoid(y).data), cuda.to_cpu(t)
y = np.asarray(y > 0.5, dtype=np.int32)
y, t = y[:, 0, ...], t[:, 0, ...]
evals = evaluations.eval_semantic_segmentation(y, t)
# 学習中のログに出力
reporter.report({'loss': loss,
'miou': evals['miou'],
'pa': evals['pixel_accuracy']}, self)
return loss
Trainerは,Optimizerの引数として渡されたモデルが「目的関数の値を返す」関数である,と考えます.最初のモデルではモデルは出力結果を返しましたが,それをL.Classifierというオブジェクトに渡した上でOptimizerに渡していました.Chainerが用意しているこのL.Classifierは,内部で目的関数の値だけでなくAccuracyも計算し,reporter.reportに辞書を渡す形でLogReportなどのExtensionが補足できるように値の報告を行います. しかし,L.ClassifierはmIoUの計算をしてくれません.
そこで,今回はL.Classifierを自前のPixelwiseSigmoidClassifierに置き換え,自分で実際の目的関数となるF.sigmoid_cross_entropyの計算を書きつつ,予測(上記コード中のy)に対してPixel AccuracyとmIoUの両方を計算して,報告するようにします.__call__自体は目的関数の値(スカラ)を返すことが期待されているので,F.sigmoid_cross_entropyの返り値であるlossだけをreturnしています.
5.5.5. 新しいモデルを使った学習¶
では,これらのモデルとカスタムClassifierを使って,Trainerによる学習を行ってみましょう.以下のセルを実行してください.
[17]:
def create_trainer(batchsize, train, val, stop, device=-1, log_trigger=(1, 'epoch')):
model = FullyConvolutionalNetwork(out_h=256, out_w=256)
train_model = PixelwiseSigmoidClassifier(model)
optimizer = optimizers.Adam(eps=1e-05)
optimizer.setup(train_model)
train_iter = iterators.MultiprocessIterator(train, batchsize)
val_iter = iterators.MultiprocessIterator(val, batchsize, repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=device)
trainer = training.trainer.Trainer(updater, stop, out='result_fcn')
logging_attributes = [
'epoch', 'main/loss', 'main/miou', 'main/pa',
'val/main/loss', 'val/main/miou', 'val/main/pa']
trainer.extend(extensions.LogReport(logging_attributes), trigger=log_trigger)
trainer.extend(extensions.PrintReport(logging_attributes), trigger=log_trigger)
trainer.extend(extensions.PlotReport(['main/loss', 'val/main/loss'], 'epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/miou', 'val/main/miou'], 'epoch', file_name='miou.png'))
trainer.extend(extensions.PlotReport(['main/pa', 'val/main/pa'], 'epoch', file_name='pa.png'))
trainer.extend(extensions.Evaluator(val_iter, train_model, device=device), name='val')
trainer.extend(extensions.dump_graph('main/loss'))
return trainer
これが今回用いるTrainerオブジェクトを作成する関数です.最初のケースと違うところは,ログをファイルに記録するLogReportや標準出力にログを指定項目を出力するPrintReport,またグラフを出力するPlotReport拡張でlossとaccuracy(ここではpa=Pixel Accuracy)だけでなくmiouも出力しているところです.
それでは学習を開始します.最初のモデルではmIoUが0.68強までしかいかなかったことを思い出しつつ,経過を見てみましょう.今回はモデルが大きくなりパラメータ数も増えているため,少し学習に時間がかかります(6分強かかります)
下記のセルを実行してください.
[18]:
%%time
trainer = create_trainer(128, train, val, (200, 'epoch'), device=0, log_trigger=(10, 'epoch'))
trainer.run()
epoch main/loss main/miou main/pa val/main/loss val/main/miou val/main/pa
10 0.217319 0.49158 0.983161 0.203718 0.491125 0.982249
20 0.0616517 0.491819 0.983639 0.0719857 0.491152 0.982304
30 0.0461788 0.493983 0.982984 0.0525315 0.492035 0.982315
40 0.0406598 0.588519 0.98567 0.047224 0.600972 0.984296
50 0.0339304 0.686925 0.989066 0.0408804 0.562657 0.984478
60 0.0257464 0.701245 0.989779 0.0302204 0.684284 0.988242
70 0.0197137 0.764356 0.992181 0.0229083 0.782138 0.991027
80 0.0231423 0.725282 0.991338 0.0245496 0.801205 0.990292
90 0.0135091 0.842669 0.994562 0.0156175 0.84005 0.993563
100 0.0111497 0.880008 0.995718 0.0139815 0.845988 0.994134
110 0.00964575 0.892643 0.996156 0.0126476 0.861745 0.994719
120 0.00856779 0.896131 0.996531 0.0118676 0.871221 0.99504
130 0.0076486 0.904866 0.996839 0.0113571 0.87839 0.995318
140 0.00667165 0.923679 0.997336 0.0115666 0.883627 0.995331
150 0.00640179 0.926811 0.997414 0.0107191 0.887169 0.99569
160 0.00542098 0.932314 0.997756 0.0105103 0.891736 0.995831
170 0.00514952 0.932478 0.997895 0.0103055 0.894193 0.995951
180 0.00542594 0.927573 0.997637 0.0107345 0.897242 0.995891
190 0.00521717 0.934435 0.997714 0.011302 0.896472 0.995793
200 0.00415518 0.945518 0.998277 0.0100966 0.902488 0.996249
CPU times: user 4min 16s, sys: 35 s, total: 4min 51s
Wall time: 5min 18s
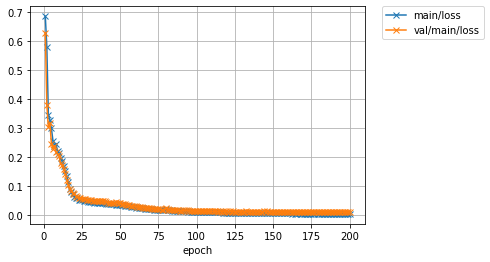
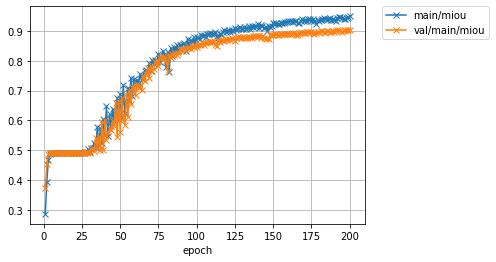
学習が終了しました.PrintReportが出力した経過の値を見る限り,mIoUが少なくとも0.90近くまで到達していることがわかります.
5.5.6. 学習結果を見てみよう¶
では,今回の学習でPlotReport拡張が出力したグラフを見てみましょう.下記の3つのセルを実行してください.
[19]:
from IPython.display import Image
print('Loss')
Image('result_fcn/loss.png')
Loss
[19]:
[20]:
print('mean IoU')
Image('result_fcn/miou.png')
mean IoU
[20]:
[21]:
print('Pixel Accuracy')
Image('result_fcn/pa.png')
Pixel Accuracy
[21]:
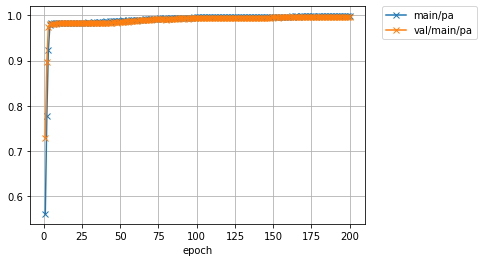
Pixel Accuracyが0.99以上であるだけでなく,mIoUも0.90近くまで上がっています.mIoUに注目すると,最初のモデル(0.68程度)と比べて随分精度が上がっていることがわかると思います.実際にvalidationデータに対して推論を行った際の予測ラベル画像を見て,結果を確認しましょう.以下のセルを実行してください.
[22]:
evaluate(trainer, val, device=0)
show_predicts(trainer, val, device=0, )
Pixel Accuracy: 0.9962486853966346
mIoU: 0.9024884891819902



一つ目のモデルの結果を確認した際と同じ画像が3つ並べられています.一つ目の結果よりも,特に3行目に注目すると,だいぶ正解ラベルに近い形のマスクを推定できていることがわかります.
畳み込み層だけからなるより深いモデルを学習に用いることで,大きく結果を改善することができました.
5.6. さらなる精度向上へのヒント¶
今回のモデルでも十分うまくいっているようにみえますがまだ性能改善の余地があります.Semantic Segmentationでは,どうやって入力画像における広い範囲の情報を1つのピクセルの予測に役立てるか,どうやって複数の解像度における予測結果を考慮するか,などが重要な問題意識となります.また,ニューラルネットワークでは一般に,レイヤを重ねれば重ねるほど,特徴量の抽象度が上がっていくとされています.しかし,Semantic Segmentationでは,正確に対象物体の輪郭を表すマスク画像を出力したいので,low levelな情報(エッジ・局所的な画素値勾配のような情報,色の一貫性など)も考慮して最終的な予測結果を作りたくなります.そのために,ネットワークの出力に近いレイヤでどうやって入力に近いレイヤで取り出された特徴を活用すればよいか,が重要になってきます.
これらの視点からいくつもの新しいモデルが提案されています.代表的なものを挙げると,例えば以下のようなものがあります.
5.6.1. SegNet [9]¶
各層でMax Poolingを適用した際に「どのピクセルが最大値だったか(pooling indices) 」の情報をとっておき,後で画像を拡大していく時に記録しておいたpooling indicesを使ってUpsamplingする手法です.ChainerCVにてChainerで実装されたモデル及び完全な再現実験を含むコードが公開されています.

5.6.2. U-Net [10]¶
下層の出力特徴マップを,上層の入力に結合することで活用する構造.全体がアルファベットの "U" のような形をしていることから「U-Net」とよばれます.セグメンテーションタスクで広く使われています.

5.6.3. PSPNet [11]¶
異なる大きさのsub-regionごとの特徴を大域的なコンテキストを考慮するために活用することで,ImageNet 2017 Scene Parsing Challengeで優勝したモデルです.

この他にも様々な手法が提案されています.例えばクラス間のサンプル数の大小だけでなく,難しいクラスと簡単なクラスがある場合にそれらを考慮した損失関数を使うことで性能をあげることができます.
また,今回は簡単のためtraining splitとvalidation splitのみを持つデータセットを使いましたが,本来はハイパーパラメータをvalidation splitでの検証結果を用いて調整したあと,最終的な性能を評価する段階でtest splitを使うべきです.
5.7. その他の参考資料¶
最後に,本資料作成者によるいくつかのセグメンテーションに関する資料をここに載せます.
また,以下のレビュー論文も昨今のDeep learningを活用したセグメンテーション手法についてよくまとまっており,参考になります.
5.8. 参考文献¶
[1] Sunnybrook cardiac images from earlier competition http://smial.sri.utoronto.ca/LV_Challenge/Data.html
[2] This "Sunnybrook Cardiac MR Database" is made available under the CC0 1.0 Universal license described above, and with more detail here: http://creativecommons.org/publicdomain/zero/1.0/
[3] Attribution: Radau P, Lu Y, Connelly K, Paul G, Dick AJ, Wright GA. "Evaluation Framework for Algorithms Segmenting Short Axis Cardiac MRI." The MIDAS Journal -Cardiac MR Left Ventricle Segmentation Challenge, http://hdl.handle.net/10380/3070
[4] https://www.kaggle.com/c/second-annual-data-science-bowl/details/deep-learning-tutorial
[5] Yusuke Niitani, Toru Ogawa, Shunta Saito, Masaki Saito, "ChainerCV: a Library for Deep Learning in Computer Vision", ACM Multimedia (ACMMM), Open Source Software Competition, 2017
[6] http://fcn.berkeleyvision.org/
[7] Long, Shelhamer, Darrell; "Fully Convoutional Networks for Semantic Segmentation", CVPR 2015.
[8] Zeiler, Krishnan, Taylor, Fergus; "Deconvolutional Networks", CVPR 2010.
[9] Vijay Badrinarayanan, Alex Kendall and Roberto Cipolla "SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation." PAMI, 2017
[10] Olaf Ronneberger, Philipp Fischer, Thomas Brox, "U-Net: Convolutional Networks for Biomedical Image Segmentation", MICCAI 2015
[11] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang and Jiaya Jia, "Pyramid Scene Parsing Network", CVPR 2017